1、ThreadLocal设计图
2、应用场景分析
3、关键类ThreadLocalMap
(1)数据结构
(2)怎么存/取数据
(3)内存回收和扩容问题
4、参考文档
1、ThreadLocal设计图
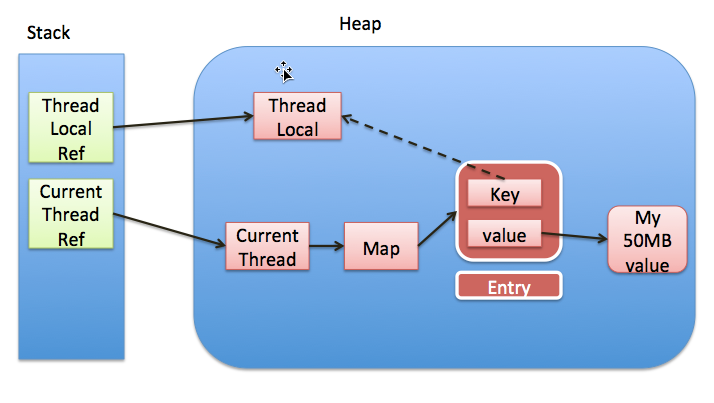
设计图分析:
一个Thread维护一个ThreadLocalMap的实例,ThreadLocalMap内部包含一个Entry[]数组,而Entry是一个key为WeakReference
是否会发生内存泄漏,其核心是是否有GC Roots开始的引用链,对于ThreadLocal要考虑的问题:
若往Entry[]数组中,put的数据越来越多,会导致ThreadLocal实例和Object value越来越多,假设ThreadLocalRef到ThreadLocal实例的引用又不断开的话,Thread也不结束的话,就会导致ThreadLocal实例和Object value不能释放,从而可能引发内存溢出或内存泄漏。(活跃的Thread可以作为GC Roots,如果Thread结束,则从Thread中所有对象都会释放。
解决思路:
(1)Thread活跃期间,定期查找key引用断开的废弃Entry,断开这个Entry到value的引用,等GC回收
(2)断开ThreadLocalRef到ThreadLocal实例的引用
不过很多用ThreadLocal的场景,每个线程的Entry[]只存了一个数据,且ThreadLocal定义成 static final类型,所以不容易出现内存溢出。如Android中的Looper就是一个线程对应一个Looper,JDBC数据库连接中也是一个线程对应一个连接。
2、应用场景分析
ThreadLocal简单说来就是:
一个Thread维护自己的一个Map,每个Thread只拿自己Map中的数据,各个Thread互不干扰,不存在什么线程间数据共享问题。Map中可以存放一个或多个数据。
比如Android中的Looper机制就是,主线程和各子线程都有自己独立的Looper实例。
比如Hibernate的JDBC数据库连接,每个线程有自己独立的Connection,互不干扰。
ThreadLocal和synchronized的比较:
都和多线程有关。区别是,ThreadLocal里各线程间的数据是没啥关联,互不干扰的。而synchronized里是数据共享的数据,同一时刻只能一个线程访问。而且ThreadLocal里需要维护一个数组,synchronized不需要维护数组。所以ThreadLocal略占内存但效率高,synchronized不占内存但效率低。也就是网上有人总结的空间换时间和时间换空间的差别。
3、关键类ThreadLocalMap
(1)数据结构
ThreadLocalMap三要素:
Entry[] table; //数组
int size; //元素个数
int threshold; //阈值,2/3数组长度,当size >= 3/4 * threshold时需要对数组扩容
Entry是<WeakReference
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
(2)怎么存/取数据
数据存取,主要是关注set/get方法。
取数据get()
1、获取当前线程
2、获取当前线程的ThreadLocalMap对象
3、当前ThreadLocal实例作为key,从ThreadLocalMap中查找对应的value,并返回结果。
具体查找过程:
(1)先计算索引,int i = key.threadLocalHashCode & (table.length - 1);
(2)如果table[i]元素非空且table[i].key == key,说明找到了,返回table[i].value
(3)否则,从i开始遍历一轮每个元素e(即从包括i开始往后直到第一个空元素,算作1轮,i有可能就是第一个空元素)。
(3.1)如果e.key == key,则说明找到并返回e.value;
(3.2)如果e.key == null,则说明是垃圾数据,调用expungeStaleEntry(i)进行垃圾数据逻辑处理即可
(3.3)如果e.key != null && e.key != key,则说明存在hash冲突,这个位置被别的对象先占了,根据线性探测法往后寻找,循环上面步骤。
4、如果没有查到,则调用初始化方法并返回初始值。
expungeStaleEntry(int staleSlot)为垃圾数据处理逻辑:
简单来说干了两件事:跑1轮,清空里面的垃圾数据,非垃圾数据重新hash。
(1)staleSlot位置的数据清空,size-1
(2)从staleSlot+1开始遍历一轮每个元素e,位置为i(即从staleSlot+1开始往后直到第一个空元素,算作1轮)
(2.1)如果e.key == null,则说明是垃圾数据,将e清空,size-1
(2.2)如果e.key != null 但 [h = e.key.threadLocalHashCode & (len - 1)] != i,说明元素e本来不应该放在位置i,当时只是因为发生hash冲突h位置被别人占了,将第i个位置置空,然后根据线性探测法重新放置元素e的位置,即找到从h开始的第一个空元素位置放进去即可。
(3)返回第一个空元素的位置。
存数据set(T value)
1、获取当前线程
2、获取当前线程的ThreadLocalMap对象
3、将<key, value>放入ThreadLocalMap中,其中key为当前ThreadLocal实例,value为外部传入Object
具体放入步骤:
(1)计算索引,int i = key.threadLocalHashCode & (len-1);
(2)从i开始遍历一轮每个元素e(即从包括i开始往后直到第一个空元素,算作1轮)
(2.1)如果e.key == key,说明找到了赋值的位置,进行赋值e.value = value并return
(2.2)如果e.key == null,说明是垃圾数据,调用replaceStaleEntry(key, value, i)处理完后并return
(2.3)否则继续遍历下一个元素
(3)将<key, value>放到第一个空元素位置,size+1。
(4)调用cleanSomeSlots(i, size)清空部分数据
(5)若一个数据也没有清空,且size >= threshold,则调用rehash重新hash
replaceStaleEntry(key, value, staleSlot)垃圾数据处理逻辑:
简单来说干了两件事:1、将<key, value>填充到staleSlot位置;2、跑一轮,找到第一个垃圾数据位置slotToExpunge,然后从slotToExpunge开始执行两轮垃圾数据清理操作
(1)从staleSlot开始走prevIndex往前回溯一轮(即从staleSlot往前回溯到第一个空元素),找到最前面的垃圾数据的位置i,将该位置记录为slotToExpunge
(2)从staleSlot+1开始往后遍历一轮每个元素e,位置为i(即从staleSlot+1往后遍历直到第一个空元素)
(2.1)如果e.key == key,说明位置找到,将table[i]和table[staleSlot]元素交换,并将<key, value>填充到table[staleSlot],此时table[i]为垃圾数据。如果前面步骤(1)中staleSlot就是第一个垃圾数据的位置,现在数据交换后第一个垃圾数据位置变成了i,将该位置记录为slotToExpunge。然后调用expungeStaleEntry(int staleSlot)执行一轮垃圾数据处理。之后再接着前一轮的空数据的位置调用cleanSomeSlots(i, size)再执行一轮清理垃圾数据。然后return
(2.2)如果e.key == null,说明是垃圾数据,再看是不是staleSlot+1开始的第一个垃圾数据,如果是的话,将该位置记录为slotToExpunge
(3)将<key, value>填充到staleSlot位置。
(4)调用expungeStaleEntry(int staleSlot)执行垃圾数据处理。之后再调用cleanSomeSlots(i, size)进一步清理垃圾数据。
cleanSomeSlots(i, size)数据清空逻辑:
从位置i开始,以二分的方式往后遍历log(n)次,并清理垃圾数据。
rehash逻辑:
(1)整体扫描一遍数组,对于每一个垃圾数据,调用expungeStaleEntry(i)执行垃圾清理操作
(2)如果size >= 3/4 * threshold,执行resize扩容操作
resize逻辑:
(1)新数组容量扩大为原来老数组的2倍
(2)将老数组里的元素依次映射到新数组(老数组垃圾数据丢弃,index计算方式k.threadLocalHashCode & (newLen - 1), 线性探测解决hash冲突)
(3)内存回收和扩容问题
内存回收:get和set过程只要遍历到垃圾数据就会来一波垃圾数据清理操作。
扩容问题:set的时候,由于数据量可能扩大,所以可能会扩容。
其他的比如threadLocalHashCode,HASH_INCREMENT = 0x61c88647看下面文章介绍即可。